Интегрированные сети ISDN
Иллюстрация работы алгоритма GCRA
Рисунок 4.3.5.3. Иллюстрация работы алгоритма GCRA
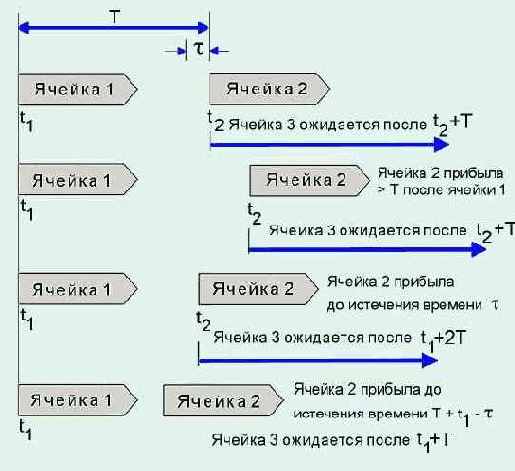
gcra имеет два параметра. Один из них характеризует максимально допустимую скорость передачи (PCR - peak cell rate; T=1/PCR - минимальное расстояние между ячейками), другой - допустимую вариацию значения скорости передачи (CDVT=L). Если клиент не собирается посылать более 100000 ячеек в секунду, то Т=10 мксек. На Рисунок 4.3.5.3 представлены разные варианты следования ячеек. Если ячейка приходит раньше чем T-t, она считается неподтверждаемой и может быть отброшена. Ячейка может быть сохранена, но при этом должен быть установлен бит CLP=1. Применение бита CLP может быть разной для разных категорий услуг (смотри таблицу 4.3.5.3.). Данный механизм управления трафиком сходен с алгоритмом "дырявое ведро", описанным в разделе "Сети передачи данных".
Можно вычислить число подтверждаемых ячеек N, которые могут быть переданы при пиковом потоке ячеек PCR=1/t. Пусть время ячейки в пути равно d. Тогда N = 1 + (l/(T-d)). Если полученное число оказалось нецелым, оно должно быть округлено до ближайшего меньшего целого.
Трудно устранимой проблемой для atm является предотвращение перегрузки на промежуточных коммутаторах-переключателях. Коммутаторы могут иметь 100 внешних каналов, а загрузка может достигать 350000 ячеек/сек. Здесь можно рассматривать две задачи: подавление долговременных перегрузок, когда поток ячеек превосходит имеющиеся возможности их обработки, и кратковременные пиковые загрузки. Эти проблемы решаются различными способами: административный контроль, резервирование ресурсов и управление перегрузкой, привязанное к уровню трафика.
В низкоскоростных сетях с относительно медленно меняющейся или постоянной загрузке администратор вмешивается лишь при возникновении критической ситуации и предпринимает меры для понижения скорости передачи. Очень часто такой подход не слишком эффективен, так как за время доставки управляющих команд приходят многие тысячи ячеек. Кроме того, многие источники ячеек в ATM работают с фиксированной скоростью передачи (например, видеоконференция).
Требование понизить скорость передачи здесь достаточно бессмысленно. По этой причине в АТМ разумнее предотвращать перегрузку. Но для трафика типа CBR, VBR и UBR не существует никакого динамического управления перегрузкой и административное управление является единственной возможностью. Когда ЭВМ желает установить новый виртуальный канал, она должна охарактеризовать ожидаемый трафик. Сеть анализирует возможность обработки дополнительного трафика с учетом различных маршрутов. Если реализовать дополнительный трафик нельзя, запрос аннулируется. В отсутствии административного контроля несколько широкополосных пользователей могут блокировать работу массы узкополосных клиентов сети, например, читающих свою почту.
Резервирование ресурсов по своей сути близко административному контролю и выполняется на фазе формирования виртуального канала. Резервирование производится вдоль всего маршрута (во всех коммутаторах) в ходе реализации процедуры setup. Параметрами резервирования может быть значение пикового значения полосы пропускания и/или средняя загрузка.
Для типов сервиса CBR и VBR отправитель даже в случае перегрузки не может понизить уровень трафика. В случае UBR потери не играют никакой роли. Но сервис ABR допускает регулирование трафика. Более того, такое управление здесь весьма эффективно. Существует несколько механизмов реализации такого управления. Так предлагалось, чтобы отправитель, желающий послать блок данных, сначала посылал специальную ячейку, резервирующую требуемую полосу пропускания. После получения подтверждения блок данных начинает пересылаться. Преимуществом данного способа следует считать то, что перегрузки вообще не возникает. Но данное решение не используется из-за больших задержек (решение ATM-форума).
Другой способ сопряжен с посылкой коммутаторами специальных ячеек отправителю в случае возникновения условий перегрузки. При получении такой ячейки отправитель должен понизить скорость передачи вдвое. Предложены различные алгоритмы последующего восстановления скорости передачи.
Но и эта схема отвергнута форумом atm из-за того, что сигнальные ячейки могут быть потеряны при перегрузке. Действительно данный алгоритм не всегда можно признать разумным. Например, в случае, когда коммутатор имеет 10 каналов с трафиком по 50 Мбит/с и один канал с потоком в 100 кбит/c, глупо требовать понижения трафика в этом канале из-за перегрузки.
Третье предложение использует тот факт, что граница пакета помечается битом в последней ячейке. Коммутатор просматривает входящий поток и ищет конец пакета, после чего выбрасывает все ячейки, относящиеся к следующему пакету. Этот пакет будет переслан позднее, а отбраcывание M ячеек случайным образом может вынудить повторение передачи m пакетов, что значительно хуже. Данный вариант подавления перегрузки был также не принят, так как выброшенный пакет совсем не обязательно послан источником, вызвавшим перегрузку. Но этот способ может быть использован отдельными производителями коммутаторов.
Обсуждались решения, сходные с тем, что используется в протоколе TCP "скользящее окно". Это решение требует слишком большого числа буферов в коммутаторах (как минимум по одному для каждого виртуального канала). После длинных дискуссий был принят за основу совершенно другой метод.
После каждых М информационных ячеек каждый отправитель посылает специальную RM-ячейку (resource management). Эта ячейка движется по тому же маршруту, что и информационные, но RM-ячейка обрабатывается всеми коммутаторами вдоль пути. Когда она достигает места назначения, ее содержимое просматривается и корректируется, после чего ячейка посылается назад отправителю. При этом появляются два дополнительных механизма управления перегрузкой. Во-первых, RM-ячейки могут посылаться не только первичным отправителем, но и перегруженными коммутаторами в направлении перегрузившего их отправителя. Во-вторых, перегруженные коммутаторы могут устанавливать средний PTI-бит в информационных ячейках, движущихся от первоисточника к адресату. Но даже выбранный метод подавления перегрузки не идеален, так как также уязвим из-за потерь управляющих ячеек.
Управление перегрузкой для услуг типа abr базируется на том, что каждый отправитель имеет текущую скорость передачи (ACR - actual cell rate), которая лежит между MCR (minimum cell rate) и PCR (peak cell rate). Когда происходит перегрузка, ACR уменьшается, но не ниже MCR. При исчезновении перегрузки acr увеличивается, но не выше PCR. Каждая RM-ячейка содержит значение загрузки, которую намеривается реализовать отправитель. Это значение называется ER (explicit rate). По пути к месту назначения эта величина может быть уменьшена попутными коммутаторами. Ни один из коммутаторов не может увеличивать ER. Модификация ER может производиться как по пути туда, так и обратно. При получении RM-ячейки отправитель может скорректировать значение ACR, если это необходимо.
С точки зрения построения интерфейса и точек доступа (T, S и R) сеть ATM сходна с ISDN (см. Рисунок 4.3.3.1 ).
Для физического уровня предусмотрены две скорости обмена 155,52 и 622,08 Мбит/с. Эти скорости соответствуют уровням иерархии SDH STM-1 и 4*STM-1. При номинальной скорости 155.52 Мбит/с пользователю доступна реально скорость обмена 135 Мбит/c, это связано с издержками на заголовки и управление. Для ATM используются коаксиальные кабели, скрученные пары (раздел 2.1). Это обеспечивает балансировку передающей линии по постоянному напряжению, но удваивает частоту переключения практически вдвое. Скрамблерный метод не меняет частоту переключения, но его эффективность зависит от передаваемой информации. CMI предпочтительней для 155 Мбит/с. В настоящее время используется две схемы передачи данных применительно к ATM: базирующийся на потоке пакетов (cell stream) и на SDH структурах. В первом случае мы имеем непрерывный поток 53-октетных пакетов, во втором эти пакеты уложены в STM-1 кадры. Управляющие сообщения располагаются в заголовках секции и пути кадра SDH. AAL (ATM adaptation layer) служит для адаптации различных видов сервиса к требованиям ATM-уровня. Каждый вид услуг требует своего AAL-протокола. Главной целью AAL является обеспечение удобства при создании и исполнении программ прикладного уровня.
Для всех AAL определены два субуровня:
| SAR | (segmentation and reassemble) делит пакеты высокого уровня, передает atm и наоборот (сборка сообщений из сегментов). |
| CS | (convergent sub-layer) зависит от вида услуг (обработка случаев потери пакета, компенсация задержек, мониторирование ошибок и т.д.). Этот подуровень может в свою очередь делиться на две секции: CPCS (common part convergence sublayer) – общая часть субуровня конвергенции и SSCS (service-specific convergence sublayer) – служебно-ориентированный подуровень конвергенции (последний может и отсутствовать). |
В настоящее время определены четыре класса услуг, которые могут требовать или нет синхронизации между отправителем и получателем, осуществлять обмен при постоянной или переменной частоте передачи бит, с установлением связи или без. Особенности этих видов услуг для адаптивного уровня систематизированы в таблице 4.3.5.4. Каждая из услуг имеет свой AAL протокол.